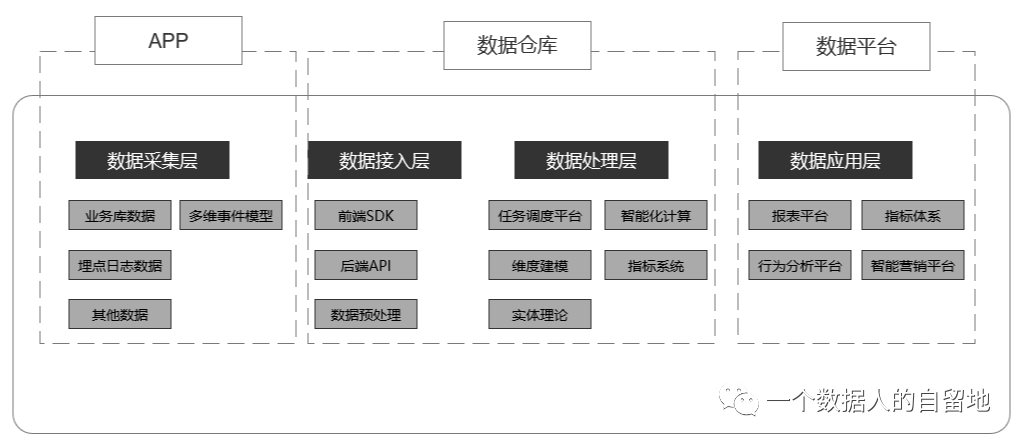
本文将从数据采集层、数据接入层、数据处理层、数据应用层这四个层次来依序展开,讲述一条数据从埋点产生,一直到最终被加工应用的过程,通过本文的阅读理解,你可以收获:
1、一个完整的数据处理链路;
2、理解数据在不同环节的加工方式;
3、对数据的流转有较为全面的认识;
01
数据是如何被采集的
数据采集是一个完整的工作流程,他需要三个标准的动作来完成:埋点、采集、上报,这也是一组数据从产生到存储必经的三个步骤。
1.1.埋点
埋点的功能是,在适当的位置,以特定的时机,以预定好的规则收集我们需要的数据的一种技术。
一方面,当用户在app中产生动作时,对于我们来说,是不可见的。所以我们需要通过埋点,把用户的行为尽可能全面,准确地记录下来。以便我们后续对数据进行挖掘分析,以可视化的方式,重新复现用户的行为。
另外一方面,除了用户的行为外,很多时候我们还需要分析其他实体的行为,比如对于我们的app来说,会在崩溃的时候发送错误日志,这其实也是一种埋点,用于分析app自身这个实体,其他还有活动,商品等等实体。
至此,我们可以给埋点重新再下一个定义:埋点是对于特定的实体,在适当的位置,特定的时机,以预定好的规则收集我们需要的数据的一种技术。
所以我们需要有一个需求文档,记录埋点的事件、埋点的位置、埋点的上报时机、以及需要收集的数据等。

1.2.收集
一旦埋点被触发,数据便会产生,埋点便会以我们预先设定好的规则去捕获特定的数据。
但程序在运行时所有的变量都是保存在内存当中的,如果出现程序重启或者机器宕机的情况,那这些数据就丢失了。埋点数据的丢失会给我们后续的分析带来困扰。
所以我们需要对内存中数据进行序列化,变成可传输的文件暂存在本地文件。为后续的上报动作做准备。一般的接口返回数据都会封装成JSON格式,比如类似下面这种:

1.3.上报
经过收集的数据从产品被送往数据接入层的动作过程就是上报。只有完成了上报成功并被存储,才能算是对实体进行一次行为的记录。
上报动作会对数据做最终把关:首先,筛查待上报数据,确保这些数据是被允许上传的,然后,按照数据协议的约定,将待上报数据以合适的方式打包,最后,建立与数据接入层的通讯,完成数据包的传送。
原则上我们是希望数据能够被及时准确地上报,但是我们并不是出于时效的需求,而是希望能够被完整且准确地记录而已。所以在开始时,对于大部分埋点,可以将多个数据进行一定的积累后统一进行上报,既能保证产品的性能,又可以减轻数据的服务器和网络负担。常见的上报策略有四种:

当完成这几步操作后,此时数据就已经脱离APP了,开始往数仓的方向流动,数仓承担着接收数据并最终将数据落地到应用的职责。
02
数据是如何被接收的
数据在到达接入层后会经历解包、解析转换、数据清洗、数据存储四个技术流程。只有经过了这一系列的步骤,数据才能够以规整的形式呈现出来,以供下一个环节的消费。
2.1.解包(反序列化)
当两个进程(前后端)在进行远程通信时,彼此可以发送来各种类型的数据。
但无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象转换为字节序列,才能在网络上传送;
接收方则需要把字节序列再恢复为对象。埋点数据在被上报的时候,是以json的格式进行压缩传输的,所以数据在到达接入层后会经历解包(也就是反序列化的操作)操作。
2.2.解析转换
在数据收集的阶段,我们收集上来的数据是按照一定的规则进行拼装的,所以到达了接入层之后,就需要对它进行解析。
首先把它每个字段对应的度量值都提取出来。然后提取出来后的数据还要经过一步转换,因为在解析后的数据类型与之前采集时定义的逻辑类型会存在差异,所以需要按照原先的定义,将每个字段的取值转换为正确的类型和格式。便于后续的处理与应用
2.3.数据清洗
而且当数据量足够大时,必定会产生“不干净”的数据。我们以脏数据来称呼这类数据。脏数据一般是指不真实、不完整、不正确、重复或无意义的数据。在数据采集和接入的过程中,产生脏数据的原因有很多,常见原因如下:
因数据采集组件未被正确配置导致一组数据缺失关键度量而不完整;
因用户产品发生异常导致上报的数据中存在错误;
因用户产品发生异常或网络传输故障导致同一组数据被重复上报。
脏数据往往无法被纠正和利用,数据清洗的目标就是尽可能地消除脏数据,并修复脏数据产生的影响。对于自动化数据产品体系而言,这一过程要通过设置各种识别规则,结合机器学习来完成,必要时也要进行人工干预,以促进自动化体系的完善。
2.4.数据存储
把数据比作客人,如果之前的三个过程是对客人的各种招待(当然也包括将不速之客拒之门外),那么数据存储就是要为客人安排住宿了,数据仓库是实现数据存储的重要技术手段。
根据数据协议和采集规则 的定义,接入层会事先在数据仓库中建立相应的表(Table),然后将接入的每一组数据依次存入表中(每一组数据在表中占据一行)。
这样看来,数据仓库就像一座大型宾馆,每一张表则是为不同体格的客人量身定制的各种不同的房间。将各表以某种时间粒度(如小时、日、周)划分分区,根据上报时间将数据分配到对应的分区中,不仅便于数据的归档存储,更有利于提高数据在今后被提取使用的效率。
最终在处理完之后,埋点日志就变成一条条的明细记录在表中,在多维事件模型中,是以大宽表的形式存在,在维度模型中,则是以事实表的形式存在。这些都是最原始的,未经过数据处理的明细数据,具体要怎么运用它们,就需要进入到我们下一步,数据处理的流程了。
03
数据是如何被处理的
数据接入层所存储的上报数据是最原始的数据形态,是一系列用户行为的明细数据,这些数据往往只是对用户行为等的事实描述,离分析和应用还隔着“处理”这关键的一层。
数据处理层通过两个基础操作:归并和计算,便可针对各种应用场景做各式各样的处理,产生各种类型的数据以供消费。
3.1.归并
归并是指从一张或多张数据二维表中选取部分数据,整理成一份“新”二维表的操作,归并处理主要有以下四种操作,选择、投影、合并、联结:
针对一份数据:
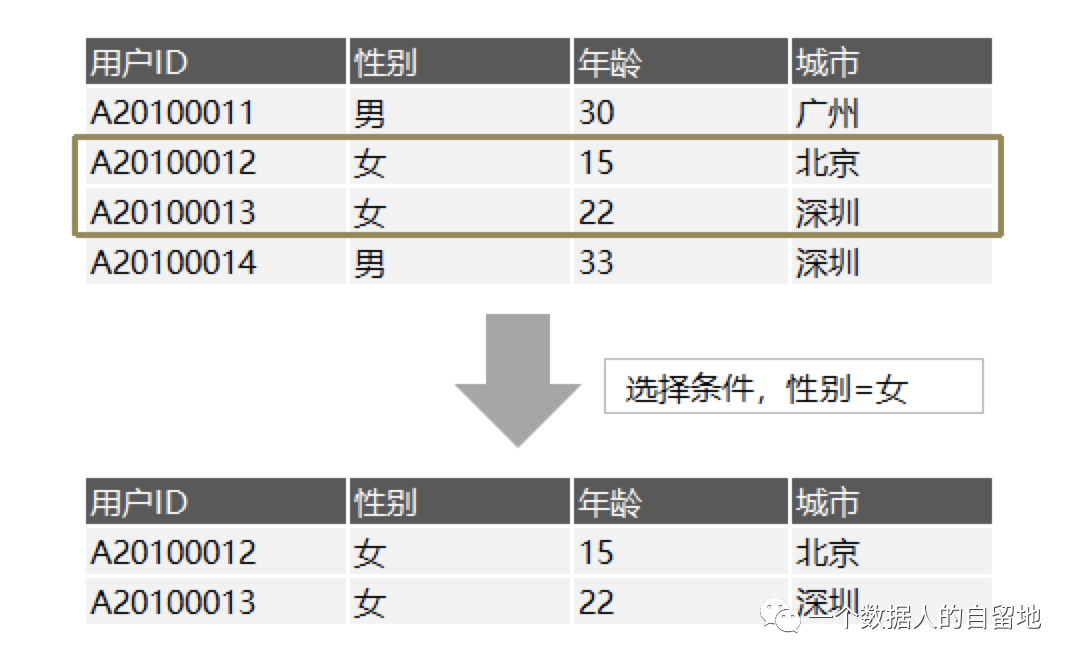
选择(Selection):将一张二维表,以一定的规则按行抽取其中部分数据形成“新”的二维表,列数不变
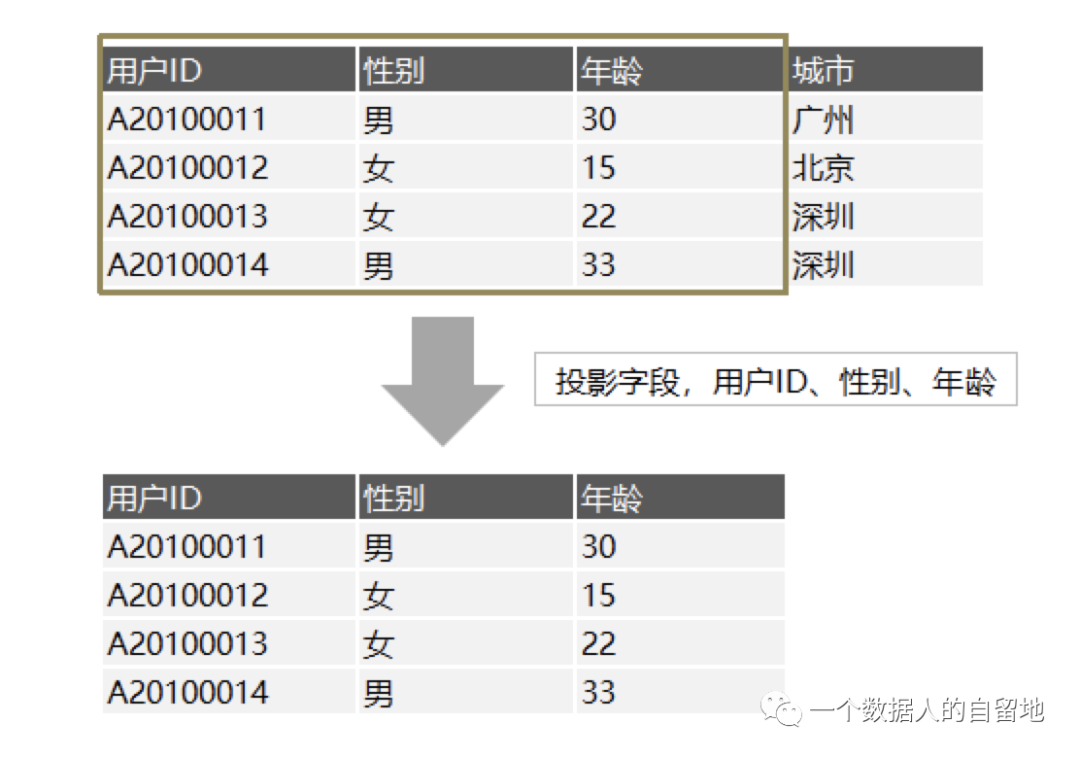
投影(Projection):将一张二维表,以一定的规则按列抽取其中部分数据形成“新”的二维表,行数不变
针对多份数据:
合并(Union):把两张二维表按行拼接成一份“新”二维表,即纵向扩展,两张二维表所有列上的字段必须相同。

连接(Join):把两张二维表按列拼接成一份“新”二维表,即横向扩展。两张二维表至少有一个相同字段作为连接键。
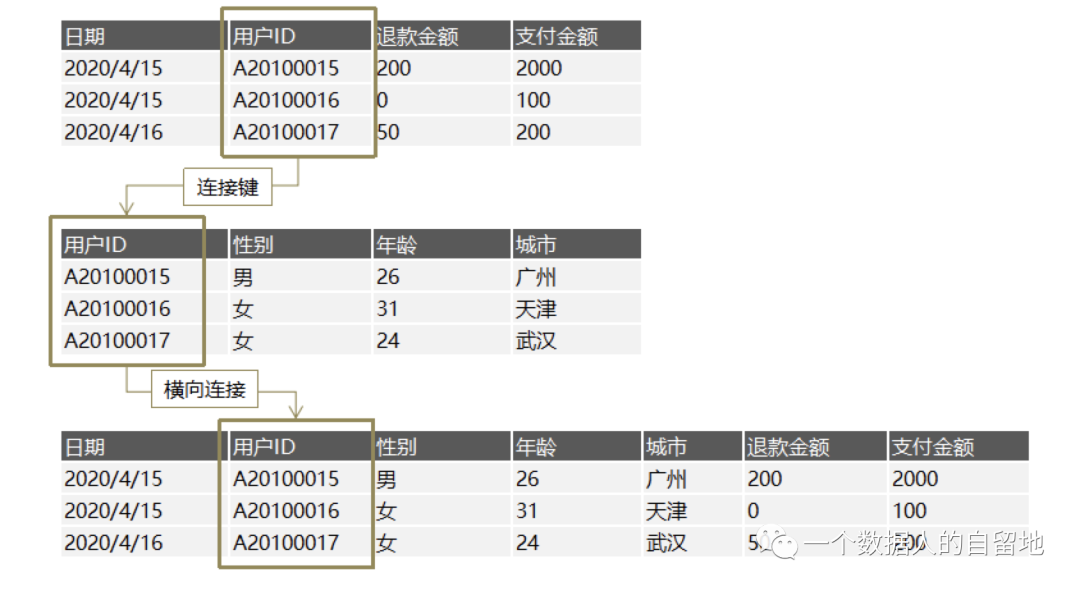
3.2.计算
这里的计算与数学中的计算概念大致相同,指通过已知数据得到未知数据的过程。在数据处理中,常见的计算操作分为两种:组合计算和聚合计算
组合计算:将二维表的不同列(维度)上的度量值进行横向计算的过程。(可以是数学运算,也可以是逻辑运算,条件运算等)

聚合计算:将二维表的同一列(维度)上的度量值进行纵向计算的过程。(一般用于统计,如计数、求和、求平均、求方差、求极值等)
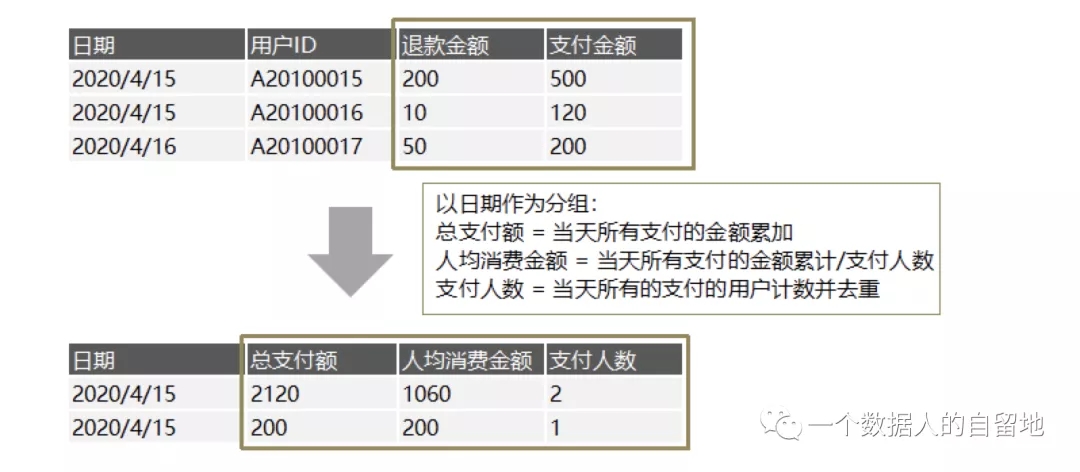
在经过一系列的归并与计算之后,数据已经被开发人员制作成具有业务意义的指标了。并且在不同的表中储存起来。于是接下来我们就可以对这些指标,进行实际意义上的应用了。
04
数据是如何应用的
在经历了采集、接入、处理这一系列流程后,数据终于到达应用层了。现在的数据虽然已经被制作成指标,但还是以一种不太友好的方式——数据表的方式呈现,所以我们要在提供的数据基础上,制作成各种数据产品,落地到业务,让数据可以真正为业务提供价值。
从发展形态来看,数据产品基本是沿着一条解决问题的逻辑路径在进化的,即发现业务问题→分析定位问题→预测业务问题→智能处理问题。
对应这个路径的数据产品则是:报表型产品(业务报表,DashBoard等)、到分析型产品(OLAP、漏斗工具、路径分析工具等)、再到策略型产品(推荐系统、流失预警系统等)、最后到智能型产品(智能运营、智能营销等)

大数据全景图
前面的几个类型的产品大家都应该是比较熟悉的,讲讲最后一个智能型产品吧。这个也是现阶段业内都在研究与探索的内容。所谓的智能型产品到底是什么呢?
其实他是前一个阶段的产品——策略型产品的一个进阶,并且引入了大量自动化的机制来减少人的操作与决策过程。
比如,你现在有一套传统的营销系统,可以按照自己的分群规则来筛选目标用户,并对设定在固定的是加你节点上,对这批用户进行触达营销。但是如果是智能营销系统的话,他的实现思路可能是这样的。你只要输入你的营销目标及活动相关的参数,比如像双11的促销活动,系统就可以基于以往的海量数据计算出不同品类的商品应该采用什么样的活动方式,对哪些类型的用户推送,在什么时候推送等等。而这一些操作,都不需要人工去干预。可能最终机器只是输出一个最终的执行方案让你点一下是否确认而已。完全释放了运营的人力,机器的数据逻辑取代了运营的经验决策。
但是,目前还没见到有比较完美的实现方案,大部分实现的都是半自动的智能型产品。虽说暂时没有,但不代表以后不可能,至少在可预见的基础,这个功能是完全有可能实现的。
05
写在最后
巧妇难为无米之炊,要掌握好一个数据产品的设计思路,就需要对产品背后的数据处理流程进行深刻的理解,去感受数据在不同处理环节中产生的价值。
但对于业内来说,暂时还没看到有比较成体系,成规范的数据全链路处理逻辑的文章。于是本文作者—“小风”与畅销书《数据产品经理修炼手册》的作者—“大鹏”,联合推出一个21天的埋点训练课程,将从数据埋点需求开始讲起,到埋点数据的入库处理,一直到最后怎么样的埋点才能打造出一个成熟的指标系统。
所有的内容制作都源自作者的日常工作实践,真正可落地,不来虚的,全程干货,诚意满满。
课程内容大纲:
课程与作业安排

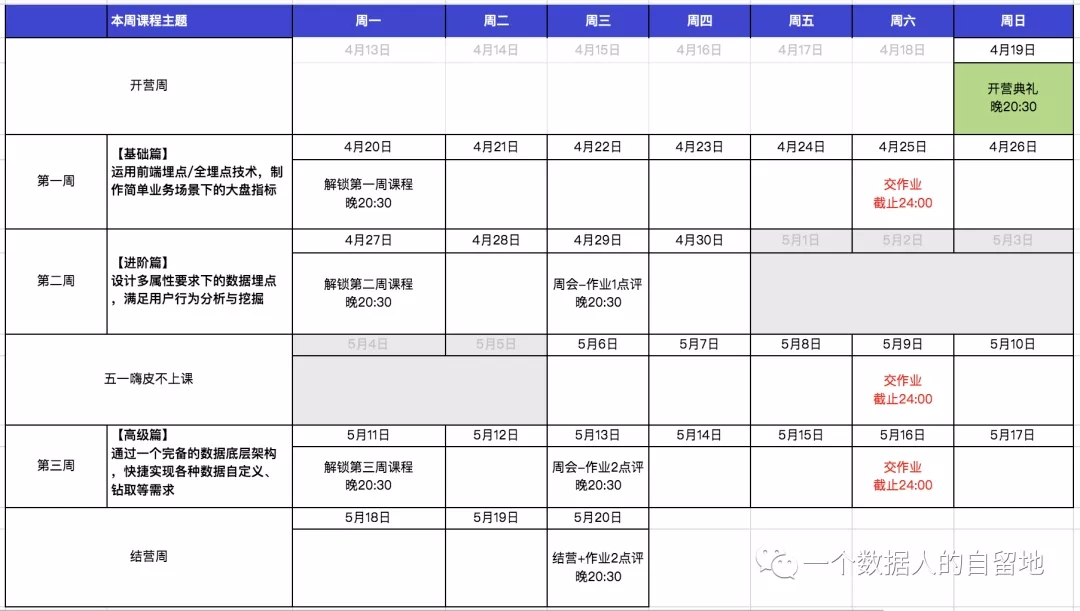
注:大家要在规定时间内交作业哦,不要错失让老师批改作业的机会
学习报名:
如果你对埋点课程感兴趣,扫描下方海报中的二维码,进入埋点课程咨询群,向小助理进行咨询吧。
注:为了保证大家的学习体验,本期学员名额限50位,目前还有19个名额,先到先得,满员即停止报名。




发表评论 取消回复