最近,老曹带的数据产品经理小王,深受数据质量的困扰,不知道怎么解决数据质量的问题,跑到老曹身边,带着求知若渴的眼神,对老曹说:
“老曹,最近在用数据的时候,发现数据质量很差,都说数据质量很重要。可是,我应该如何改善呢。老曹,快给我讲讲吧!”

老曹一听,这小伙越来越可以啊,主动学习的心态越来越好了,心中还是很满意的:
“好的,那我先给你想一下数据质量的重要性吧。之所以要强调数据质量的重要性,因为它是数据产品的基础,它会影响到数据仓库、商业智能、数据分析平台、数据应用等各个方面。同时,影响数据质量的因素又有很多,包括数据埋点质量、数据传输过程中出现的问题,数据口径是否一致等等。
随着业务发展,数据量呈爆炸式增加,数据发挥的价值越来越大,数据质量问题也变得越来越严重,低质量的数据不仅使用不便,还会误导决策,甚至灾难性的结果,数据质量的好坏,决定了数据是否能够真正发挥价值。“
数据产品经理小王:
“这些我都知道,赶紧接着往下说,接着讲,如何来判断数据质量的高低呢?!!!”

老曹笑一笑,娓娓道来:
“好吧,这是个好问题,如何判断数据质量的高低呢?什么样的数据是高质量的呢?
引用美国著名的质量管理学家朱兰博士(J.M.Juran)的一句话:If they are fit for their intended in operations, decision making and planning.翻译一下,就是,如果根据这些数据做出的操作、决策和规划,符合之前的预期,那么这些数据就是高质量的,换个角度来理解,高质量的数据可以真实反映它们所代表的主体信息。
结合大数据与业务经验,在从定性的角度来看,影响数据质量的因素包括数据完整性、数据正确性、数据一致性、数据的可获取性以及数据的时效性等方面。
数据的完整性是指业务涉及到数据是完整的,能够对业务使用影响很大的数据都要保持一定的完整性;
数据的正确性要满足准确性和精准性两方面,即数据要是准确无误的,数据要在精度上满足业务需求;
数据的一致性要满足同一个指标的口径要一致,数据不要有二义性;
数据的可获取性是指使用数据的时候,数据是被有效组织的,并且能够被高效获取;
数据的时效性指使用的业务数据都是最新的,而不是无效的过期数据。
”

数据产品经理小王:
“哦,原来有这么多方面觉得数据质量啊,那作为一个数据产品经理,应该如何搭建数据质量产品的产品架构呢,都应该包含哪些产品模块或者功能啊?”
老曹在画板上抹去刚才写的东西,继续画起来:
“确实,为了保证数据质量,有资源和精力的公司会搭建自己的数据管理系统,我给你画一下数据管理中心产品架构,主要包含指标体系管理、全局数据管理、元数据管理等。另外,在数据安全性的前提下,还可以通过全局数据接口对外输出高质量的数据。
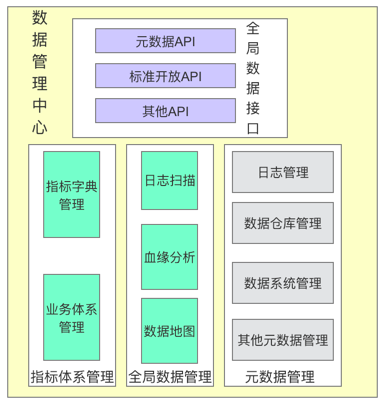
数据管理中心产品架构
以数据管理系统为例,它侧重于从时效性和数据一致性这两大质量方向保证数据的可读性。
在检查数据仓库的数据时效性方面,要明确每天的每一个层级、每一个数据表的最早和最晚生成时间,发现影响当天数据生成延误的数据表,并能够通过数据管理系统回答以下问题:
当天 MySQL 表和 Hive 表中的核心指标是何时生成的? 有哪些表的产出时间比预期时间延迟了? 任务延迟的原因是由哪几张表造成的? 瓶颈在哪里?优化哪几层?哪几张表可以提高核心指标等的生成时间?”
数据产品经理小王如有所思的说:
“嗯嗯,是啊,时效性很重要,现在经常有数据延迟产出,我可以根据你刚才讲的做一些日常的检测和监控了。”
老曹接着说:
“是啊,另一个很重要的是数据仓库的数据一致性检查。
通过数据一致性检查,在数据质量视图的展现下,我们可以快速了解存在依赖关系的数据表的分维度数据变化情况。为了对数据一致性进行检查,大数据管理系统项目需要做的事情主要分为以下几步:
第一步,建立数据依赖引擎,实现依赖图谱。依赖图谱用于构建数据仓库表之间的分层级依赖关系,然后存入MySQL表并能支持可视化展现,如图2所示。
第二步,计算数据准备情况。各个表、各个分区的数据准备就绪时间按天、小时级进行汇总。根据Hive仓库的Meta信息可以获取Hive表各个分区的创建时间,根据创建时间确定数据的实效性,用来分析展现每天、每小时的状态和瓶颈。如果需要对MySQL进行验证,则通过SQL语句查询的方式获取对应时间在MySQL中是否存在。
第三步,建立数据计算引擎。根据定义的小时级指标、天级别指标规则,结合数据表各个分区的准备就绪时间,调用Spark SQL计算核心指标。
第四步,数据比较引擎。根据表和表之间核心指标的关系、表和表之间的规则进行比较验证。例如,A = B,A + B = C,B/A < 0.95等逻辑判断。”

数据管理系统依赖图谱
数据产品经理小王点点头:
“嗯嗯,是啊,我赶紧拿着小本本去学习消化下。”
老曹点点头:
“到吃饭的时间了,等我们吃完饭回来学习也不迟啊,其实我给你讲的这些只是一个概览,更多的还需要你在以后的工作中多实践,多尝试。你也一定会做出更多不错的数据质量产品的,数据质量也会进一步提升,加油啊。”

后续,公众号“一个数据人的自留地”会持续更新老曹入职公司后,作为数据产品经理的工作过程中的经历和心得,希望对各位有所帮助和启发,如果有共鸣,也欢迎大家留言、投稿,让“一个数据人的自留地”,成为一个有温度的数据社区。

一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。
扫码关注我,带你探索数据的神奇奥秘





发表评论 取消回复